GMP
GMP
GMP
安装
以下是针对一个没有 root 权限的 linux 操作系统的安装流程。
- 在 ubuntu/debian 上可以使用
sudo apt install libgmp-dev安装- 在 MacOS 上可以使用
brew install gmp安装
- 首先下载源文件。
1
wget https://gmplib.org/download/gmp/gmp-6.3.0.tar.xz
- 解压tarball。
1
tar -xf gmp-6.3.0.tar.xz
- 配置构建过程
1 2
cd gmp-6.3.0 ./configure --prefix=$HOME/gmp # 因为没有 root 权限, 只好安装到这
- 编译 & 安装
1
make -j$(nproc) && make install
测试程序 - gmp_test.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include <stdio.h>
#include <gmp.h>
int main() {
// Initialize GMP variables
mpz_t a, b, sum, difference, product, quotient;
mpz_init(a);
mpz_init(b);
mpz_init(sum);
mpz_init(difference);
mpz_init(product);
mpz_init(quotient);
// Set values for a and b
mpz_set_str(a, "123456789012345678901234567890", 10);
mpz_set_str(b, "987654321098765432109876543210", 10);
// Perform arithmetic operations
mpz_add(sum, a, b);
mpz_sub(difference, a, b);
mpz_mul(product, a, b);
if (mpz_cmp_ui(b, 0) != 0) {
mpz_tdiv_q(quotient, a, b);
} else {
gmp_printf("Division by zero is not allowed.\n");
}
// Print results
gmp_printf("a = %Zd\n", a);
gmp_printf("b = %Zd\n", b);
gmp_printf("a + b = %Zd\n", sum);
gmp_printf("a - b = %Zd\n", difference);
gmp_printf("a * b = %Zd\n", product);
gmp_printf("a / b = %Zd\n", quotient);
// Clear GMP variables
mpz_clear(a);
mpz_clear(b);
mpz_clear(sum);
mpz_clear(difference);
mpz_clear(product);
mpz_clear(quotient);
return 0;
}
编译运行
1
2
gcc -O2 -o gmp_test gmp_test.c -I$HOME/gmp/include -L$HOME/gmp/lib -lgmp
./gmp_test
与 Python 比较
\[\pi = \sum_{k=0}^{\infty}\left[\frac{1}{16^k}(\frac{4}{8k+1}-\frac{2}{8k+4}-\frac{1}{8k+5}-\frac{1}{8k+6})\right]\]下面的 python 代码根据 BBP 公式计算圆周率的前100000个有效16进制位
1
2
3
4
5
6
7
8
9
10
11
ans = 0
v = 100008
tmp = 16 ** (v)
for k in range(v):
a = tmp * 4 // (8 * k + 1)
b = tmp * 2 // (8 * k + 4)
c = tmp // (8 * k + 5)
d = tmp // (8 * k + 6)
ans += a - b - c - d
tmp //= 16
print(hex(ans)[2:-8])
使用 gmp 的 c++ 代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
#include <gmp.h>
#include <cstdlib>
#include <cstdio>
#include <cstring>
int main() {
mpz_t ans, v, tmp, base;
mpz_t a, b, c, d, denom;
unsigned long int k;
char *res_str;
mpz_init(ans);
mpz_init_set_ui(v, 100008); // v = 100008
mpz_init(tmp);
mpz_init_set_ui(base, 16);
mpz_pow_ui(tmp, base, mpz_get_ui(v)); // tmp = 16^v
mpz_init(a);
mpz_init(b);
mpz_init(c);
mpz_init(d);
mpz_init(denom);
for (k = 0; k < mpz_get_ui(v); ++k) {
// Calculate a = tmp * 4 // (8 * k + 1)
mpz_mul_ui(a, tmp, 4);
mpz_set_ui(denom, 8 * k + 1);
mpz_fdiv_q(a, a, denom); // Floor division
// Calculate b = tmp * 2 // (8 * k + 4)
mpz_mul_ui(b, tmp, 2);
mpz_set_ui(denom, 8 * k + 4);
mpz_fdiv_q(b, b, denom);
// Calculate c = tmp // (8 * k + 5)
mpz_set_ui(denom, 8 * k + 5);
mpz_fdiv_q(c, tmp, denom);
// Calculate d = tmp // (8 * k + 6)
mpz_set_ui(denom, 8 * k + 6);
mpz_fdiv_q(d, tmp, denom);
// Update ans: ans += a - b - c - d
mpz_sub(a, a, b);
mpz_sub(a, a, c);
mpz_sub(a, a, d);
mpz_add(ans, ans, a);
// Update tmp: tmp //= 16
mpz_fdiv_q_ui(tmp, tmp, 16);
}
res_str = mpz_get_str(NULL, 16, ans);
printf("%.*s\n", (int)strlen(res_str) - 8, res_str);
free(res_str);
mpz_clear(ans);
mpz_clear(v);
mpz_clear(tmp);
mpz_clear(base);
mpz_clear(a);
mpz_clear(b);
mpz_clear(c);
mpz_clear(d);
mpz_clear(denom);
return 0;
}
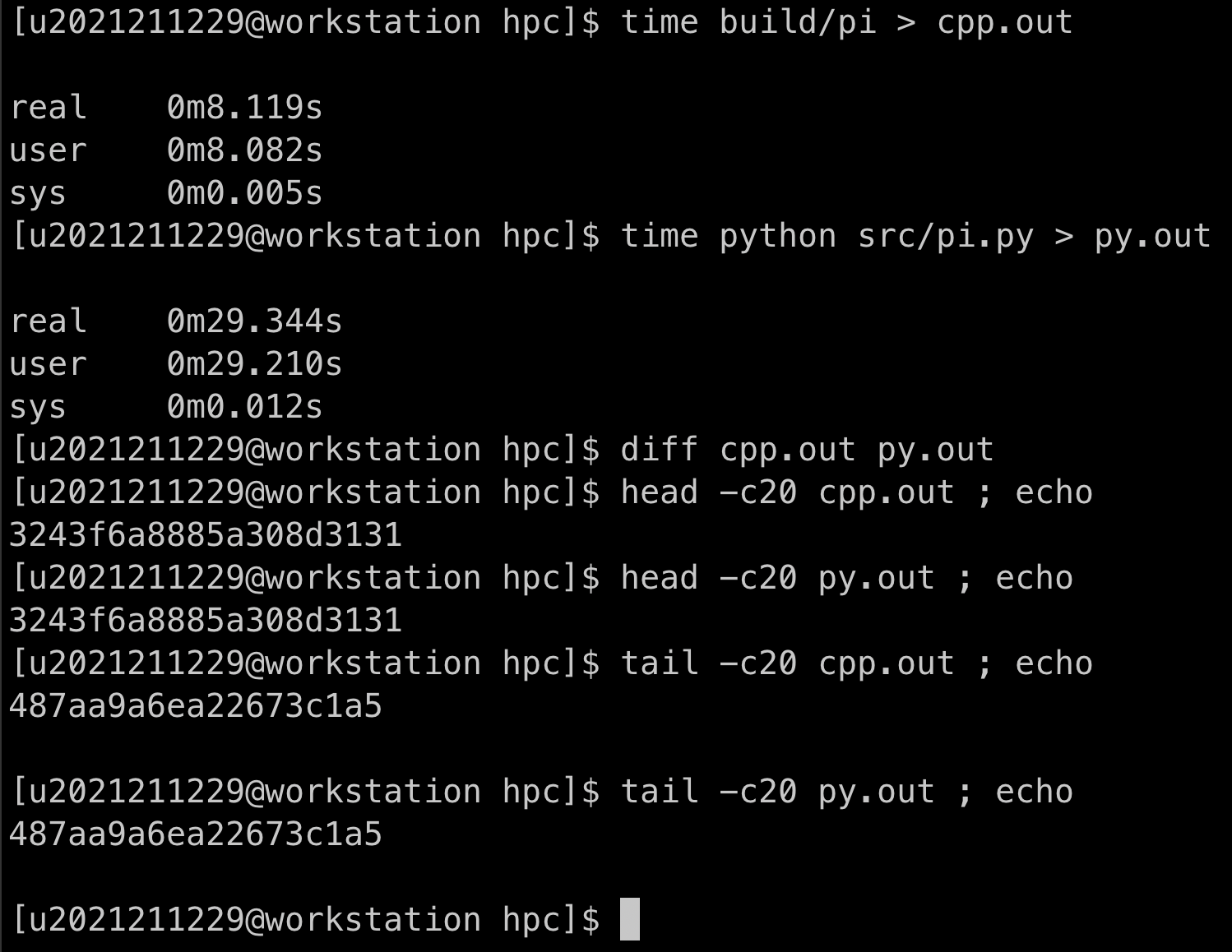
在测试机上运行的情况如下, 可以看到两个得出的结果一致, 但是python要比c++慢了3倍多。
测试机的配置在后面给出。
思考两个问题:
- 为什么在这种情况下python要比c++慢?
- 如何进行进一步加速?
机器配置
下面是 lscpu 显示的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Silver 4314 CPU @ 2.40GHz
Stepping: 6
CPU MHz: 1000.000
CPU max MHz: 2401.0000
CPU min MHz: 800.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 1280K
L3 cache: 24576K
NUMA node0 CPU(s): 0-15
NUMA node1 CPU(s): 16-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect wbnoinvd dtherm ida arat pln pts avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid fsrm md_clear pconfig flush_l1d arch_capabilities
This post is licensed under CC BY 4.0 by the author.