Vitis HLS for Llama2 Acceleration (Part 1)
Vitis HLS for Llama2 Acceleration (Part 1)
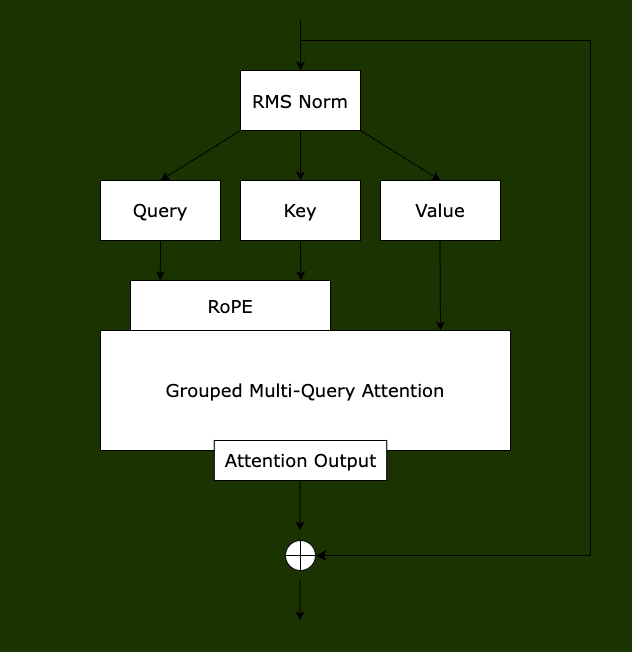
Llama2 Layer Region 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
// attention rmsnorm
rmsnorm(s->xb, x, w->rms_att_weight + l*dim, dim);
// key and value point to the kv cache
int loff = l * p->seq_len * kv_dim; // kv cache layer offset for convenience
s->k = s->key_cache + loff + pos * kv_dim;
s->v = s->value_cache + loff + pos * kv_dim;
// qkv matmuls for this position
matmul(s->q, s->xb, w->wq + l*dim*dim, dim, dim);
matmul(s->k, s->xb, w->wk + l*dim*kv_dim, dim, kv_dim);
matmul(s->v, s->xb, w->wv + l*dim*kv_dim, dim, kv_dim);
// RoPE relative positional encoding: complex-valued rotate q and k in each head
for (int i = 0; i < dim; i+=2) {
int head_dim = i % head_size;
float freq = 1.0f / powf(10000.0f, head_dim / (float)head_size);
float val = pos * freq;
float fcr = cosf(val);
float fci = sinf(val);
int rotn = i < kv_dim ? 2 : 1; // how many vectors? 2 = q & k, 1 = q only
for (int v = 0; v < rotn; v++) {
float* vec = v == 0 ? s->q : s->k; // the vector to rotate (query or key)
float v0 = vec[i];
float v1 = vec[i+1];
vec[i] = v0 * fcr - v1 * fci;
vec[i+1] = v0 * fci + v1 * fcr;
}
}
// multihead attention. iterate over all heads
int h;
#pragma omp parallel for private(h)
for (h = 0; h < p->n_heads; h++) {
// get the query vector for this head
float* q = s->q + h * head_size;
// attention scores for this head
float* att = s->att + h * p->seq_len;
// iterate over all timesteps, including the current one
for (int t = 0; t <= pos; t++) {
// get the key vector for this head and at this timestep
float* k = s->key_cache + loff + t * kv_dim + (h / kv_mul) * head_size;
// calculate the attention score as the dot product of q and k
float score = 0.0f;
for (int i = 0; i < head_size; i++) {
score += q[i] * k[i];
}
score /= sqrtf(head_size);
// save the score to the attention buffer
att[t] = score;
}
// softmax the scores to get attention weights, from 0..pos inclusively
softmax(att, pos + 1);
// weighted sum of the values, store back into xb
float* xb = s->xb + h * head_size;
memset(xb, 0, head_size * sizeof(float));
for (int t = 0; t <= pos; t++) {
// get the value vector for this head and at this timestep
float* v = s->value_cache + loff + t * kv_dim + (h / kv_mul) * head_size;
// get the attention weight for this timestep
float a = att[t];
// accumulate the weighted value into xb
for (int i = 0; i < head_size; i++) {
xb[i] += a * v[i];
}
}
}
// final matmul to get the output of the attention
matmul(s->xb2, s->xb, w->wo + l*dim*dim, dim, dim);
// residual connection back into x
for (int i = 0; i < dim; i++) {
x[i] += s->xb2[i];
}
Dataflow Analysis
HLS Components
RMSNorm
Original software implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void rmsnorm(float* o, float* x, float* weight, int size) {
// calculate sum of squares
float ss = 0.0f;
for (int j = 0; j < size; j++) {
ss += x[j] * x[j];
}
ss /= size;
ss += 1e-5f;
ss = 1.0f / sqrtf(ss);
// normalize and scale
for (int j = 0; j < size; j++) {
o[j] = weight[j] * (ss * x[j]);
}
}
HLS hardware implementation.
1
Softmax
Original software implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void softmax(float* x, int size) {
// find max value (for numerical stability)
float max_val = x[0];
for (int i = 1; i < size; i++) {
if (x[i] > max_val) {
max_val = x[i];
}
}
// exp and sum
float sum = 0.0f;
for (int i = 0; i < size; i++) {
x[i] = expf(x[i] - max_val);
sum += x[i];
}
// normalize
for (int i = 0; i < size; i++) {
x[i] /= sum;
}
}
HLS hardware implementation.
1
QKV Linear Layer
RoPE
Grouped Multi-Query Attention
Integration
References
This post is licensed under CC BY 4.0 by the author.